Something went wrong while submitting the form. Please try again.
We will use the information you provide to respond to your inquiry and communicate with you about our services. We do not sell or share personal information. For more information, see our Privacy Policy.
Feb 19, 2026
Engineering
Clueso: how we built an agent that autonomously resolves 78% of bugs
Ryan Moffat
Matthew Busel
Basis's internal Atlas team was created with a single mandate: use AI to make every employee at Basis dramatically more productive. As Basis scaled, on-call engineering work scaled with it, and Atlas identified bug investigation as one of the highest-leverage areas for automation.
That's why we built an agent called Clueso to manage incident response.
Clueso pulls error logs, writes queries, steps through our monorepo, and then delivers a verifiable post-event summary.
Routine issues resolve in under five minutes. Complex investigations can run for over an hour. Clueso now debugs more than 78% of incidents on the first pass, allowing our engineers to respond faster and allocate time to higher leverage efforts.
Getting an agent to solve simple bugs was straightforward. Getting it to solve complex bugs at the consistency required to actually change how engineers work was a different problem entirely. We wanted to write a post explaining the technical decisions that got us there, most of which generalize to any long-running agent for knowledge work.
Peter (engineer) describing his experience using Clueso
The prototype came fast
Clueso runs in a Modal VM using the Claude Agent SDK as a harness. The Agent SDK gave us a filesystem environment, flexible hooks for customizing behavior, easy integration with our observability platform, and auto-compaction out of the box. Clueso's initial environment was a minimal sandbox: our monorepo, a tool to query data, and access to our logging service. Even with just these integrations, Clueso could handle a meaningful subset of incidents almost immediately.
This is consistent with what most teams find when building agents. The first 60% of capability comes quickly. The remaining 40% is where the real work begins.
Verification is easier than generation
To expand Clueso's capabilities, we set up a simple development loop: give Clueso bugs where the root cause was already confirmed, and ask it to reproduce the diagnosis. Verifying a known answer is a much simpler task for an LLM than open-ended investigation, so when Clueso couldn't verify, the failure pointed directly at a missing capability rather than a hard problem. Maybe it needed access to an internal service API, or it didn't understand a product feature well enough to reason about the failure.
Rather than manually auditing every failure, we asked Clueso itself to diagnose these gaps, generate clarifying questions, and identify the right person to route them to. This let us prioritize the highest-impact improvements without extensive manual triage. Clueso's accuracy climbed quickly as a result.
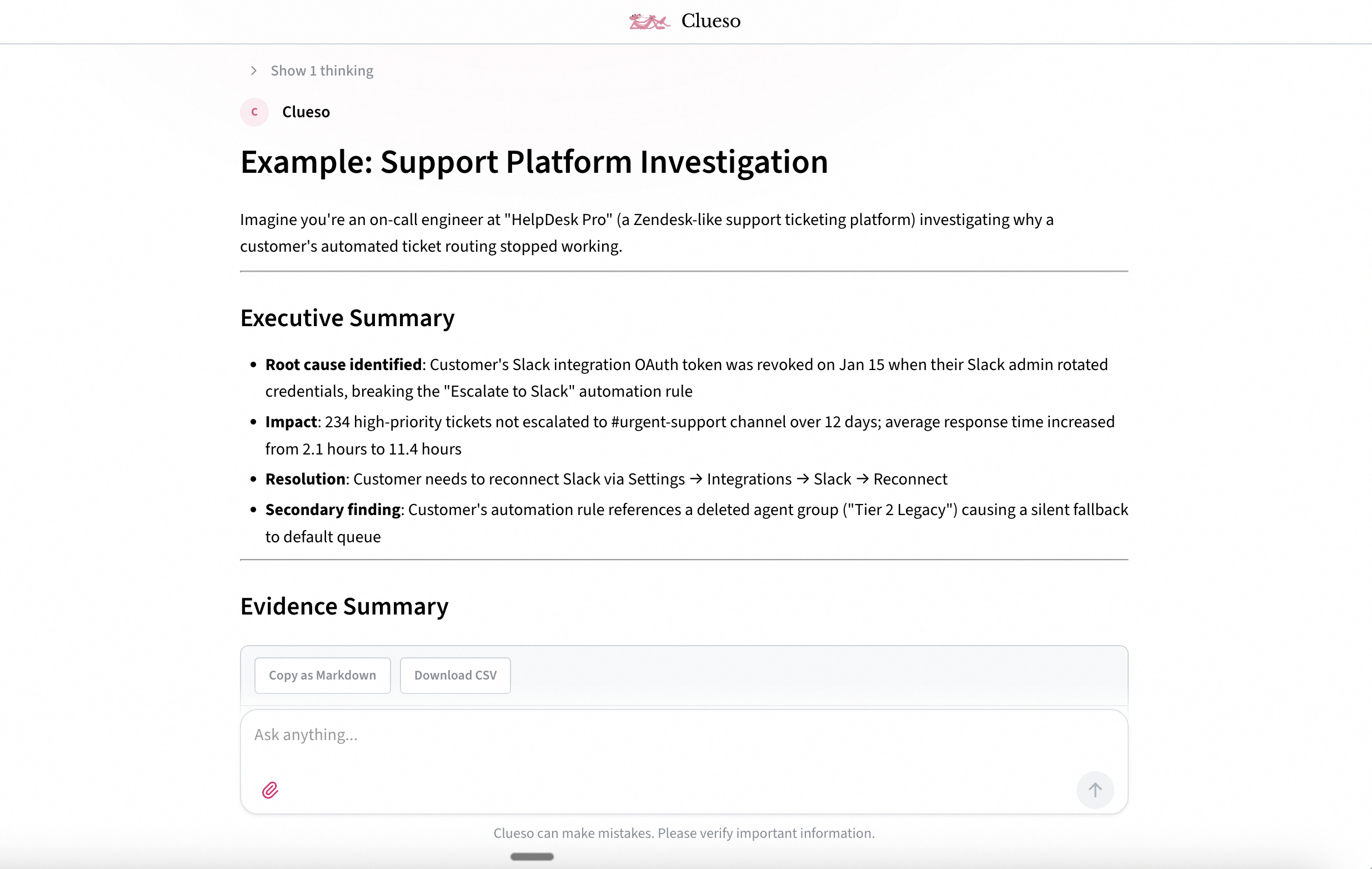
Clueso sharing an example investigation report
Tool design compounds over long trajectories
This feedback loop rapidly filled gaps in Clueso's environment. Suddenly, it became meaningfully useful for routine investigations.
But complex, long-running investigations were more stubborn. Clueso could verify a root cause when pointed in the right direction and produce clear timelines backed by evidence, but it struggled to connect the dots independently.
A number of the failures we found followed a consistent pattern:
During short investigations, Clueso used tools effectively and could work around gaps in its understanding.
Over long-running tasks, its tool use degraded as context accumulated and compaction eroded earlier reasoning.
A rock can drive a single nail, but you wouldn’t build a house with one. We found the same compounding effect in Clueso’s tool use: over short investigations, rough tool interfaces could be worked around. Over long trajectories, the tool that was good enough for a five-turn investigation became a source of cascading confusion and a primary failure mode.
To find these problems, we collected sample trajectories and had Clueso self-reflect to identify failure modes. Clueso surfaced ways to restructure tools to eliminate footgun cases where tool responses contained irrelevant or conflicting information, and these self-iterations improved its reliability across long trajectories.
But the specific fixes mattered less than the approach: we didn't engineer every improvement by hand. We trusted the system to diagnose its own weaknesses, then used those insights to guide our work.
We believe this self-diagnostic feedback loop is a core competency of building agentic systems.
Fighting compaction with a filesystem workflow
Early in development, we chose to have Clueso operate in a full filesystem environment, running shell commands and executing Python scripts to acquire context. Beyond our core repo, we gave Clueso access to on-call runbooks, internal debugging guides, and customer-facing product documentation. Runbooks were particularly valuable as they contain prewritten flows for diagnosing common errors, are easily modified, and can be loaded into context during a trajectory. This pattern has since become more mainstream with the introduction of agent skills, which Clueso now uses.
*(Example runbook excerpt)*# Agent Trajectory DebuggingAnalyze LLM/agent traces in our eval platform to debug failures.
If the issue you are analyzing is in any way potentially related to
an agent/LLM call misbehaving, then make sure to follow these
instructions and analyze the traces to understand better what's
going on. This is critical, even if you have a strong hypothesis
for the root cause, analyze the traces to be safe.
After ANY analysis, always provide direct quotes from the agent's
reasoning and actions. The user needs actual evidence, not just
summaries.
...
Over the course of an investigation, Clueso makes dozens of tool calls across potentially hundreds of turns. We noticed that during long-running investigations, detailed tool results were lost to compaction, degrading performance. Because Clueso already had full filesystem access, the fix was natural: we instructed it to save tool results to files locally. This let it capture larger amounts of context and avoid information loss when compaction occurred.
Saving tool results helped, but the conclusions drawn from analyzing those results could still be lost or distorted. Clueso might have results from a dozen queries saved to its filesystem, undergo compaction, and forget which specific object had a null field that caused a downstream bug. To address this, we had Clueso maintain a progress document modeled after a researcher's logbook: current hypotheses, references to evidence files, things it has ruled out, and next steps.
The progress document also served as the basis for Clueso's final output, which made the transition from investigation to report more reliable.
ETL sync failure investigation
Current understanding: OAuth token expired
Evidence: see query_result_003.json, row 47 shows token_expires_at
in the past
Ruled out:
- Rate limiting (no 429s in logs)
- Schema changes (checked API version)
Next: Check if token_expires_at matches the error time window
Clueso generally followed our guidance on maintaining the logbook, but we found it helpful to add intermittent hooks that prompted it to update the document and revisit our instructions. These nudges were a small addition, but in tandem with the progress document they made a noticeable difference in keeping long investigations on track.
Structured output as a termination condition
The ultimate output of a Clueso investigation is a message to our engineering team. Our guiding principle was that the output should contain everything expected in a proper post-event summary, in an easily verifiable format. Particularly as we exposed Clueso to the team for the first time, engineers needed to be able to trust and trace its reasoning.
One failure mode we encountered was early stopping. As Clueso's context window filled, it would preemptively end its turn and produce a speculative answer before gathering all the required information. Clueso needed to understand that it was in full control of when its work terminated, and that it should only stop when the success conditions were met. To address this, we added an explicit statement in Clueso's prompt that its context would be automatically compacted, and we gave it a concrete definition of "done."
We instructed Clueso to produce a timeline of events with a corresponding evidence table linking to logs and sample queries, drawn directly from its progress document. Requiring this strict structure, with clear causal links between events, had dual benefits: it made human verification straightforward, and it gave Clueso a clear termination condition. Instead of deciding when it had "done enough," Clueso could evaluate whether its evidence graph was complete.
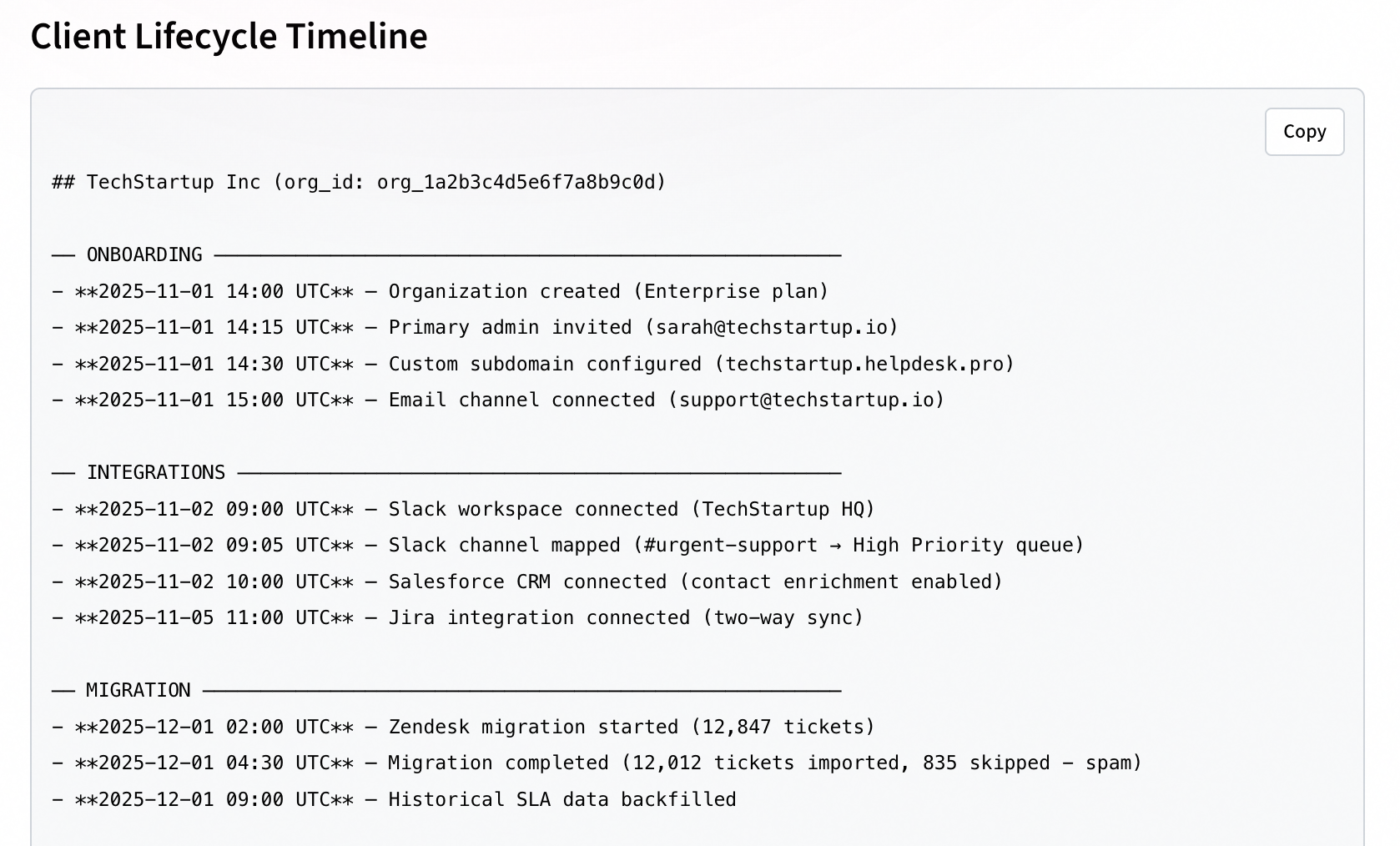
Example of a timeline Clueso might produce
From experiment to product
With Clueso reliably solving investigations, we assumed adoption would be immediate. It wasn't. Engineers need high confidence that changing their workflow is worthwhile. Moving Clueso from a powerful experiment to a tool the team relies on required a series of product decisions beyond agent engineering.
Clueso started as a standalone chat interface. This worked for early adopters, but most incident collaboration already happens in Slack via Pylon’s Slack integration. Engineers and customer support share context and discuss potential bugs in threads. In response, we added a Slack integration that let engineers tag Clueso on any thread. Clueso reads the chat, treats its contents as initial context for investigation, then replies in the same thread when finished. Usage and visibility increased immediately.
In certain channels, engineers were tagging Clueso on nearly every thread, so we automated it. For a subset of channels, Clueso now triggers on every message and replies with its findings. Our customer support channel was a natural fit. Any time a customer reaches out, Clueso investigates immediately.
Because Clueso has access to our product documentation alongside the codebase, it can distinguish between genuine bugs and cases where the customer needs guidance rather than a fix. Sometimes the issue is a misunderstanding of how a feature works, or user error.
Our support team now effectively has an on-call engineer by their side at all times, which has dropped response times on complex questions by almost 50%.
The Slack integration had the added benefit of creating a viral loop. The more Clueso appeared in public channels, the more teammates became aware of it, which drove further usage. With a handful of targeted UX decisions, Clueso went from an internal experiment to something the entire team depends on daily.
Looking to the future
Many of the techniques in this post work around current limitations in context length and long-horizon reasoning. As models improve, some will become unnecessary. The progress document might eventually be redundant when context windows are large enough and compaction is lossless. Explicit termination conditions may matter less when models can better evaluate their own completeness.
But the core challenge of getting an agent to perform consistently over long, complex tasks is not going away. We're solving these problems every day here at Basis.
If you're interested in pushing the performance and reliability of agentic systems on long-horizon tasks, we're hiring.