Something went wrong while submitting the form. Please try again.

.png)
Managing human workflows is more complex than writing code
When I began my on-call rotation last winter, I started looking for patterns by making a spreadsheet, posting stacktraces and grouping them manually. It worked; we quickly identified the alert types responsible for roughly 80% of the volume. But our vision is to build a truly AI-native company.
So I decided to automate on-call.
The core problem was that resolving issues was split between two unconnected workflows managed in two separate Slack channels. Customer complaints arrived through one channel, staffed by our Deployed Intelligence (DI) team, while automated system errors came through another. A user reporting stale General Ledger (GL) data might be caused by the same underlying bug showing up as an exception in the system channel, but we were only making that connection if the on-call engineer happened to notice both. Most of the time, the on-call would push an immediate fix, create a ticket for root-cause investigation, and move on.
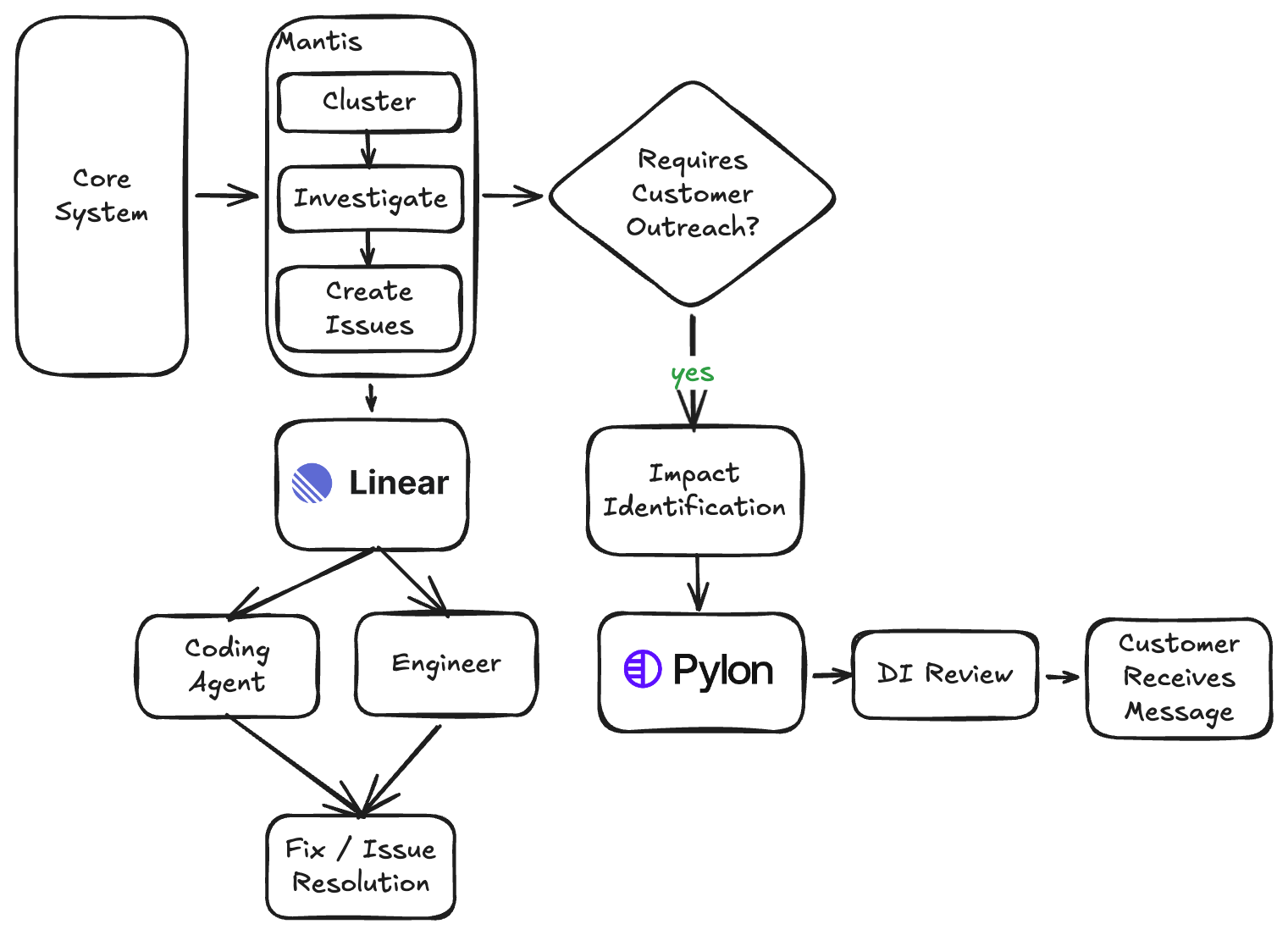
Each of these tasks - maintaining attention across repetitive alerts and pattern-matching across disconnected channels - was a natural fit for LLMs. So I built Mantis, an orchestration layer extending from raw alert ingestion all the way to drafting customer communication (though a person approves anything that reaches customers).
The system we ended up building was a strong first step. Before Mantis, being on-call consumed at least 90% of the on-call engineer's time; with Mantis, it was reduced to about one-third, without any degradation in the overall level of customer support. But adoption of the system by our engineers was mixed. This after action report covers the technical decisions we made, as well as the challenges we encountered, as we made our first foray into automating on-call.
At Basis, bugs are investigated by an agent called Clueso. Clueso has access to our monorepo, BetterStack logs, and our unified MCP server. Clueso traces function interactions across the codebase, queries internal systems, and generates root-cause analyses. This saves about 20 minutes of manual debugging time per complex investigation.
We considered third-party options for the overall workflow but determined we would be uncomfortable plugging Clueso into an external product because that would have exposed deep access to our codebase, databases, and logs to a vendor.
So Mantis became an orchestration layer around Clueso and also a notification system that extends all the way to customer communication. It runs as a Python/FastAPI application with a daemon process that operates sequential processing loops.
The final result of these steps are reports containing all the necessary information and data for a human engineer to reproduce, fix, and verify the bug and its resolution.
The primary technical challenge raised by Mantis has been weighing the use of LLM intelligence versus deterministic pattern matching. Proper issue clustering ended up requiring both approaches.
We had alerts that were scoped to particular users where errors would be identical except for a different UUID. The smaller models we used for this task were surprisingly bad at grouping these together, even though a human would do so easily. The solution was simple: deterministic normalization first. Strip the variable fields with regex, then compare structures.
There were also cases where alerts with different structures should also be clustered together. For example, a reconciliation error in different months could have different alert structures, such as "reconciliation error" and "GL tie-out exception." These could be the same issue if our system ingested malformed GL data. We erred on the side of less de-duplication: running an investigation too many times was less costly than missing a truly different error.
We rolled Mantis out gradually, maintaining redundancy with our original workflow. We continued to publish alerts to our Slack channels while also feeding them to the Postgres database for processing by Mantis. We added more alert classes to this dual-publish pattern over time, increasing the volume of data Mantis processed.
To close the investigation loop, Mantis includes an issue-management routine that creates Linear tickets and assigns them to an engineer by parsing git history to determine original authorship. Optionally, it also sends the ticket directly to a coding agent for an automated fix.
On-call engineers generally appreciated Mantis. Rather than manually scan multiple Slack channels, they would monitor the unified Mantis dashboard, which bubbled new issues to the top. By the time a human saw an issue, most of the initial assessment - investigation, root cause analysis, customer impact analysis - had already been automated and completed.
The impact of Mantis that most surprised us was what happened after triage. In most incident management systems, the pipeline ends with the creation of an engineering ticket. The questions, “Which customers were affected, and should we tell them?” are generally a separate, manual process. We automated part of it.
When an on-call engineer reviews an issue in the Mantis dashboard and determines that it impacts customers, they can trigger a specialized outreach investigation. A second Clueso agent queries internal systems and produces a structured result that includes a recommendation (reach out or just monitor), a customer-friendly summary of what happened, a list of impacted users grouped by firm, and a pre-drafted customer message.
Here's what an actual auto-generated outreach ticket looks like (lightly redacted):
The system then automatically creates one Pylon support ticket per affected firm, using a database uniqueness constraint to prevent duplicate tickets. Each ticket lands in our DI team’s queue already matched to the correct customer account, complete with the draft message, a users-with-access table, and internal technical notes.
The on-call engineer's total involvement in this entire flow is about 30 seconds. The DI team member reviews the pre-drafted message, adjusts tone if needed, and sends it.
In addition to Mantis’s clear benefits, two challenges emerged relatively quickly.
Challenge #1: Confidently wrong investigations. Agent investigations could sometimes be wrong - convincingly, confidently wrong - and verifying investigations took almost the same amount of time as conducting an original inquiry. For senior engineers who couldn't be fooled as easily, Mantis was a huge help because they could validate, or invalidate, an investigation. But for more junior engineers, the agent's logic often seemed sufficiently plausible (without being fully concrete). For example, we noticed that Clueso would often cite “race conditions” as the reason for an error when in fact the underlying issue was something else entirely. When an erroneous report was validated by an engineer and acted upon, it created more work for the team.
As Andrej Karpathy observed, writing code (generation) and reading code (discrimination) are different capabilities. There is a corollary in investigating issues: conducting an investigation and reading an investigation are different skills. To deeply understand a system, an engineer must take time wrestling with nuances, going down wrong paths, and chasing down correlated logs. When AI does that wrestling for you, you lose the muscle memory and can't always tell when the AI got it wrong. Over time, this eroded trust in the system.
Challenge #2: Incomplete adoption. Mantis didn't have the benefit of full internal network effects because it was an experimental side project rather than an organizational refactor of our overall on-call structure. A lot of work continued to be done outside the Mantis framework and the Linear tickets it created, so when an engineer did see an issue on Mantis, it might not reflect operational reality within the team. At times an issue raised by Mantis had already been fixed by someone else without being marked.
This was not a technical deficiency. But from a human workflow perspective, the fact that Mantis was being used by only half the technical staff - the on-call people but not the day-to-day engineering teams - made the system far less effective. This led to an adoption-versus-iteration problem: the best way to iterate on Mantis and improve it would be through wider adoption, but the fact that it wasn't perfect undermined adoption.
Mantis is still running. The core alert pipeline continues to process alerts and the customer outreach automation remains one of our most-used internal workflows. Our DI team relies on it as a primary channel for proactive customer communication. But the automated investigation and triage features have seen reduced adoption. On-call engineers increasingly use Mantis as a utility layer - looking up specific error codes from prediction pushes, checking alert lineage, viewing prediction payloads - rather than an overall orchestration interface.
We're exploring three directions: proactive scanning that continuously monitors logs for anomalies that haven't triggered alerts yet; a resolution feedback loop that verifies whether deployed fixes actually resolve the underlying issue, using this signal to improve future investigations; and auto-fixing low-risk issues like config updates and typo fixes, where changes could merge automatically after passing tests without human review.
But the biggest remaining lever is organizational, not technical. The customer outreach pipeline succeeded because it delivered clear value to a specific team (DI) who adopted it as their own. The investigation pipeline stalled because it asked engineers to change how they work without making that change feel inevitable. If we could go back, we'd spend more time making Mantis the canonical place where operational state lives.
If you’re interested in working with AI-native engineers who experiment, learn, and iterate, we’re hiring.
Peter Wang is a Member of Technical Staff at Basis. Seth Schiesel contributed to this post.



